前言:一个越来越常见的设计失败
过去一年我们见过的最典型的 Multi-Agent 系统失败,不是哪个 Agent 性能不够,而是「三个 Agent 各自为政,输出互相矛盾」。
最常见的架构是:定义一个 Orchestrator Agent,再定义三个 Worker Agent,Orchestrator 负责分解任务,Worker 分别执行,最后汇总输出。听起来合理。实际上,当任务复杂度上升,这个架构会快速失效:
- Orchestrator 成为单点瓶颈,所有决策都要经过它
- Worker 之间没有任何直接通信,信息必须绕道 Orchestrator
- 当任务需要跨 Worker 的协商和权衡时,系统无法处理
这类失败不是实现问题,是心智模型问题。当我们把 Multi-Agent 系统设计成「一个领导 + 若干执行者」时,就已经把多 Agent 系统降维成了一个更贵的单 Agent 系统。
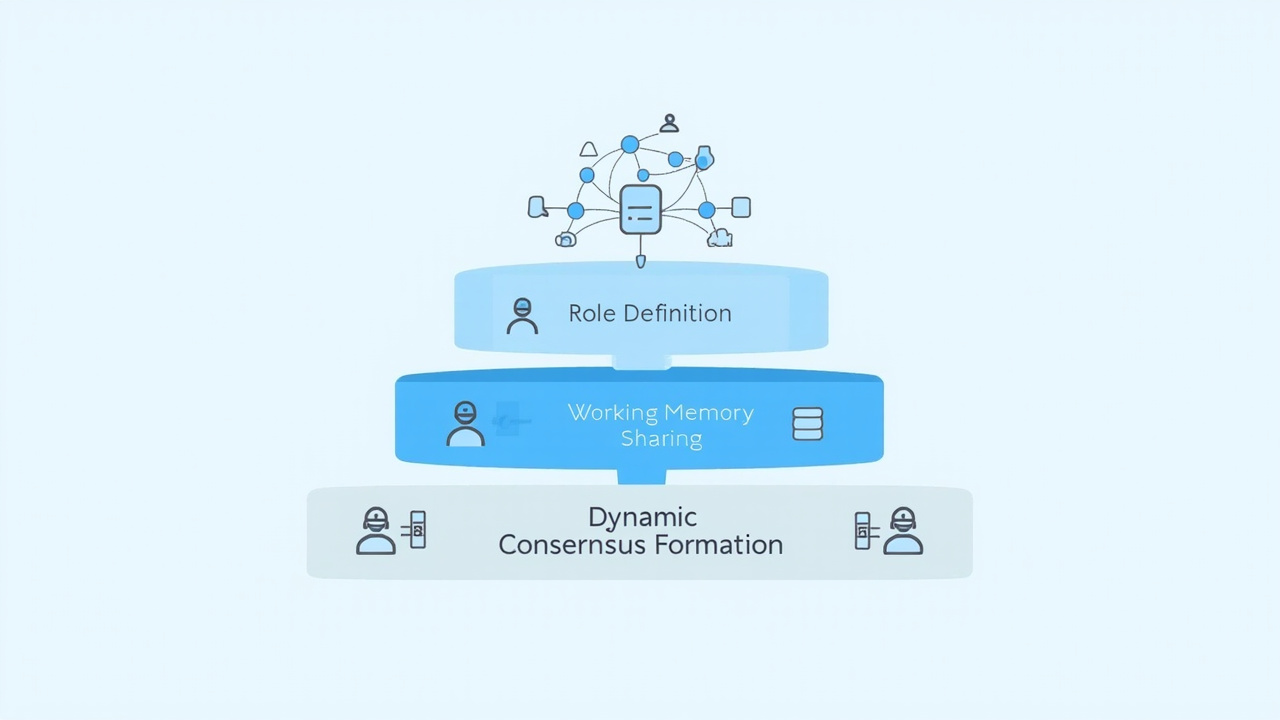
2026 年的 Multi-Agent 系统正在发生方法论层面的范式转移。本文提出多 Agent 协作的三层心智模型:角色定义 → 工作记忆共享 → 动态共识形成,这是三种不同层次的协作深度,对应不同的系统复杂度和适用场景。
第一层:角色定义(Role Definition)
这是最基础的 Multi-Agent 协作层,在这一层里,每个 Agent 被赋予一个明确、稳定的社会角色。
角色心智模型
传统的单 Agent 系统,Agent 的行为由 prompt 决定。Multi-Agent 系统的第一步,是把 prompt 层级的行为定义升级为角色定义。
角色定义 = 职责边界 + 决策权限 + 汇报关系以软件开发场景为例:
| 角色 | 职责边界 | 决策权限 | 汇报关系 |
|---|---|---|---|
| Architect Agent | 系统设计、技术选型 | 架构级决策,可否决实现方案 | 向 PM Agent 汇报 |
| Coder Agent | 代码实现、单元测试 | 实现细节决策 | 向 Architect Agent 汇报 |
| Reviewer Agent | 代码审查、质量评估 | 质量评估结论,可要求返工 | 向 Architect Agent 汇报 |
| PM Agent | 需求澄清、优先级判断 | 范围和优先级决策 | 向用户(Human)汇报 |
这个结构的本质是用组织架构的逻辑来设计 Agent 系统。每个角色的定义越清晰,Agent 的行为就越可预测,协作摩擦就越小。
角色定义的关键实践
实践一:角色的「退出条件」比「进入条件」更重要
大多数 Multi-Agent 系统的设计只关注「什么情况下 Agent 应该做什么」,忽略了「什么情况下 Agent 应该停下来等待」。
一个高质量的角色定义,必须包含明确的退出条件:
Architect Agent 的退出条件:- ✓ 架构设计文档已通过 Reviewer Agent 的评审- ✓ 所有关键技术决策已记录并获得 PM Agent 确认- ✗ 遇到超出范围的技术问题 → 升级给 PM Agent- ✗ 实现方案与架构设计存在不可调和的矛盾 → 触发重新设计流程没有退出条件,Agent 会一直「在做事」,直到任务完成或 token 耗尽。两种情况都不是你想要的结果。
实践二:角色冲突是设计问题,不是调试问题
当两个 Agent 对同一件事做出了不同判断,很多团队的第一反应是「调一调 prompt」。但这通常解决不了问题。
角色冲突通常意味着角色定义本身存在边界模糊。Architect Agent 和 Reviewer Agent 都认为某个实现方案有问题,但理由不同——这实际上是角色定义的职责重叠没有提前发现。
解决角色冲突的方法是重新审视角色定义,而不是调整 prompt。检查:两个角色的决策权限是否真的不重叠?汇报关系是否明确?
第二层:工作记忆共享(Working Memory Sharing)
角色定义解决了「谁来做什么」的问题,但 Agent 之间仍然缺乏实时共享的「上下文」。第二层协作心智模型是工作记忆共享。
工作记忆 vs 长期记忆
在单 Agent 系统里,上下文窗口(Context Window)承担了工作记忆的功能。Agent 通过「把所有相关信息都放进去」来保持状态。
Multi-Agent 系统里,这个方法失效了。当 Agent A 处理了问题的某个部分,Agent B 需要知道 Agent A 做了什么——但 B 的上下文窗口里没有 A 的工作记录。
工作记忆共享是解决这个问题的机制:多个 Agent 共享同一个读写的工作记忆空间,Agent 的输出写入共享空间,其他 Agent 可以读取。
实现形态
形态一:共享黑板(Shared Blackboard)
最直觉的实现。所有 Agent 把输出写到一块「黑板」上:
[Architect Agent] 写入:系统架构图 v1.2,包含 3 个微服务,API Gateway 设计 ↓[Reviewer Agent] 读取黑板 → 发现架构图中某处缺少错误处理 ↓[Reviewer Agent] 写入黑板:Review 意见 #3,需要在 Payment Service 增加熔断机制 ↓[Architect Agent] 读取黑板 → 处理 Review 意见这个形态的缺点是:所有 Agent 都需要持续监听黑板变化,实现复杂度较高。适合协作紧密、信息频繁交换的场景。
形态二:向量记忆数据库(Vector Memory)
把每个 Agent 的关键输出用向量编码,存入共享的向量数据库:
Agent A 输出 → 提取关键信息 → 向量化 → 存入共享 Vector DBAgent B 查询 → 从 Vector DB 召回相关记忆 → 结合自身上下文处理这个形态适合信息量大但交换频率不高的场景。每个 Agent 可以按需检索其他 Agent 的工作成果,不需要实时同步。
形态三:结构化状态机(Structured State Machine)
把多 Agent 协作建模为一个状态机,每个 Agent 负责某个状态的处理:
class MultiAgentState(Enum): REQUIREMENTS_PARSING = "requirements_parsing" ARCHITECTURE_DESIGN = "architecture_design" CODE_IMPLEMENTATION = "code_implementation" CODE_REVIEW = "code_review" TESTING = "testing" DEPLOYMENT = "deployment"
# 每个 Agent 负责处理特定状态的转换def architecture_agent(state: MultiAgentState) -> MultiAgentState: if state == MultiAgentState.REQUIREMENTS_PARSING: return MultiAgentState.ARCHITECTURE_DESIGN elif state == MultiAgentState.CODE_REVIEW: if review_result.needs_redesign: return MultiAgentState.ARCHITECTURE_DESIGN # 退回重做 return state状态机形态适合协作流程相对固定、可预测的场景。缺点是不够灵活,遇到非预期状态转换时需要人工介入。
工作记忆共享的核心挑战:一致性
当多个 Agent 并发读写共享记忆时,一致性成为问题。
问题场景:Agent A 读取了某个共享状态,Agent B 在此期间修改了该状态,A 用旧状态做了决策。
解决方案一:读写锁(悲观并发)
with shared_memory.write_lock(): agent_a.modify(state)
# 其他 Agent 在 A 释放锁之前无法写入适合写操作少、并发高的场景。
解决方案二:版本号机制(乐观并发)
current_version = shared_memory.get_version()# Agent A 和 Agent B 同时读取 version=5# Agent A 先写入,version 变为 6# Agent B 写入时检测到版本冲突,重新读取后再写入适合读多写少、冲突概率低的场景。
解决方案三:事件溯源(Event Sourcing)
不直接修改状态,而是追加事件:
[Event] AgentA: 架构设计完成,v1.2[Event] AgentB: Review 发现问题,要求补充熔断[Event] AgentA: 更新架构设计,v1.3[Event] AgentC: 测试通过当前状态 = 所有事件的重放结果。好处是任何时刻都可以回溯到任意历史状态,缺点是状态重建成本较高。
第三层:动态共识形成(Dynamic Consensus Formation)
前两层解决的是「谁来做什么」和「信息怎么传递」的问题。第三层解决的是更复杂的问题:当 Agent 之间存在利益冲突或判断分歧时,怎么形成决策?
为什么需要共识机制
考虑这个场景:
- Architect Agent:认为应该用微服务架构,理由是「可扩展性强」
- Coder Agent:认为应该用单体架构,理由是「开发速度快,当前团队规模小」
- PM Agent:认为应该用模块化单体,理由是「平衡速度和可扩展性」
三个 Agent 都有合理理由,但结论不同。在没有共识机制的系统里,通常是 PM Agent(最「高级」的 Agent)说了算,或者三个 Agent 各自按自己的理解执行,结果是系统里同时存在三种设计思路。
动态共识形成是让 Agent 之间通过某种机制收敛到统一决策的系统设计。这不意味着「少数服从多数」,而是让 Agent 能够理性地评估彼此的论据,最终形成经过充分讨论的决策。
三种共识形成模式
模式一:仲裁模式(Arbitration)
引入一个专门的仲裁 Agent,它的角色是评估其他 Agent 的建议,并做出最终决策:
Architect Agent 提出方案 ACoder Agent 提出方案 BPM Agent 提出方案 C ↓[Arbitrator Agent] 评估三个方案: - 方案 A:技术优秀,但开发周期 3 个月 - 方案 B:开发快,但扩展性差 - 方案 C:折中方案,开发周期 1.5 个月,扩展性可接受 ↓[Arbitrator Agent] 决策:采用方案 C,并向三个 Agent 解释决策依据仲裁模式的优点是决策速度快,缺点是仲裁者本身可能成为瓶颈,且决策质量取决于仲裁者的能力。
模式二:辩论模式(Debate)
多个 Agent 针对同一问题各自提出方案,然后交叉辩论,最终通过更优的论据形成共识:
Architect Agent: 微服务架构,因为「未来扩展需要」Coder Agent: 单体架构,因为「当前团队只有 3 个人,微服务的运维复杂度超出能力」Reviewer Agent: 评估 Architect 的论据 → 质疑「当前阶段真的需要考虑未来扩展吗?」Architect Agent: 重新评估 → 修正观点「如果当前阶段不考虑,未来重构成本可控」Coder Agent: 修正方案「模块化单体,在架构上预留服务拆分接口」 ↓[共识形成] 最终决策:模块化单体架构,带有清晰的服务边界定义辩论模式适合复杂决策场景,多个 Agent 有不同的专业视角,需要充分交换信息才能收敛。缺点是通信成本高,需要多轮交互。
模式三:投票模式(Voting)
每个 Agent 对不同选项投票,按某种规则(多数、权重、优先级)汇总结果:
votes = { "microservices": [architect_vote, qa_vote], "monolith": [coder_vote], "modular_monolith": [pm_vote]}
def weighted_vote(votes: dict, weights: dict) -> str: """按角色权重计算票数""" scores = {} for option, voter_list in votes.items(): scores[option] = sum(weights[voter] for voter in voter_list) return max(scores, key=scores.get)
weights = { "architect": 2.0, # 技术决策权重高 "coder": 1.5, # 实现可行性权重 "pm": 1.5, # 业务价值权重 "qa": 1.0}投票模式适合决策维度明确、可量化的场景。缺点是「票数」本身需要预先定义权重,而这个权重的定义本身可能是有争议的。
共识机制与人类的边界
一个重要的设计原则:涉及人类利益或需要人类背书的决策,不应该由 Agent 共识机制决定。
典型场景:
- 涉及财务支出的决策(即使 Agent 都「同意」某个方案,最终仍需人类审批)
- 涉及合规或法律风险的决策
- 影响用户隐私的决策
对这些场景,共识机制的作用应该是整理和呈现 Agent 之间的分歧点,帮助人类做最终决策,而不是代替人类做决策。
三层心智模型的工程实践路径
从哪一层开始
如果你的任务相对简单、流程固定:从第一层(角色定义)开始就够了。很多 Multi-Agent 系统的复杂度是人为制造的——明明可以用单 Agent 解决,非要上多 Agent。
如果你的任务涉及多步骤、跨阶段的流程:从第一层 + 第二层开始。角色定义解决分工问题,工作记忆共享解决信息传递问题。
如果你的任务涉及复杂判断、多方权衡:在第一层和第二层的基础上,引入第三层(共识机制)。但要注意,第三层会显著增加系统复杂度和通信成本,引入要谨慎。
常见的实现陷阱
陷阱一:Agent 数量过多
我们见过的最离谱的生产系统有 47 个 Agent。维护 47 个 Agent 的角色定义、工作记忆同步和共识机制,是一项巨大的工程负担。
建议:从 2-3 个 Agent 开始。只有当某个 Agent 的职责边界明显无法与其他 Agent 合并时,才拆分出新的 Agent。
陷阱二:跳过第一层直接实现第三层
直接实现「Agent 辩论」听起来很酷,但没有明确的角色定义,Agent 之间的辩论缺乏锚点——没有谁对什么问题有最终发言权,辩论容易发散。
陷阱三:共识机制变成了「谁最后说话谁赢」
有些系统的「共识机制」实际上是让每个 Agent 轮流发言,最后一个 Agent 的结论被采纳。这不是共识,这是顺序决策。
真正的共识机制要求 Agent 重新评估自己的立场,接受其他 Agent 提出的有力论据。如果一个「共识」只是简单采纳了最后一个发言者的观点,这不是共识,这是独裁。
结语
Multi-Agent 系统的协作心智模型,从浅到深是三层:
- 角色定义:谁做什么,怎么汇报
- 工作记忆共享:信息怎么流通,怎么保持一致
- 动态共识形成:分歧怎么处理,决策怎么收敛
大多数团队的多 Agent 系统问题,都可以追溯到心智模型的某一层没有做好:
- 「三个 Agent 输出矛盾」→ 角色定义不清
- 「后面的 Agent 不记得前面的工作」→ 工作记忆共享缺失
- 「两个 Agent 各执一词,系统无法收敛」→ 共识机制缺失或设计不当
想清楚你的问题属于哪一层,比直接「上多 Agent 系统」更重要。
本文首发于 MosuoAI,AI Agent 开发者的深度指南。